PDFファイルは、1つのファイルに複数のページがあるので、ファイルを取り込んだ後、認識するページを指定します。
PDFファイルを認識するにはこちらの方法を使います。ファイルを登録するには次の2つの方法があります。
ファイルダイアログで指定する
エクスプローラからファイルをドロップする
サイドバーのファイルボタンを押すと「開く」ダイアログが開きます。ここで登録するPDFファイルを選びます。 複数のPDFファイルを1度に登録することはできません。複数登録する場合はは1つずつ選んで登録します。
PDFファイルは登録時にテキストPDFか画像PDFかを検出するため1つずつの登録になります。
検出結果はキャプションバーに[画像認識][テキスト認識]と表示されます。また[テキスト認識]の場合は楽譜の背景が赤っぽくなります。
画像と判断されたPDFは、画像に変換されるため、通常の画像ファイルと同じようにあとで追加(複数登録)することができます。
テキストと判断されたPDFは、1つだけの登録となり、あとで追加や途中のページの削除などはできません。
PDFファイルはエクスプローラからドロップしても登録できます。
(複数のファイルを同時には登録できません。1つずつ選んで登録します。)
初回起動時などライセンス認証のために管理者で起動している場合は、エクスプローラと権限が違うためドロップでの登録はできません。 体験版も管理者で起動するためドロップでの登録はできません。
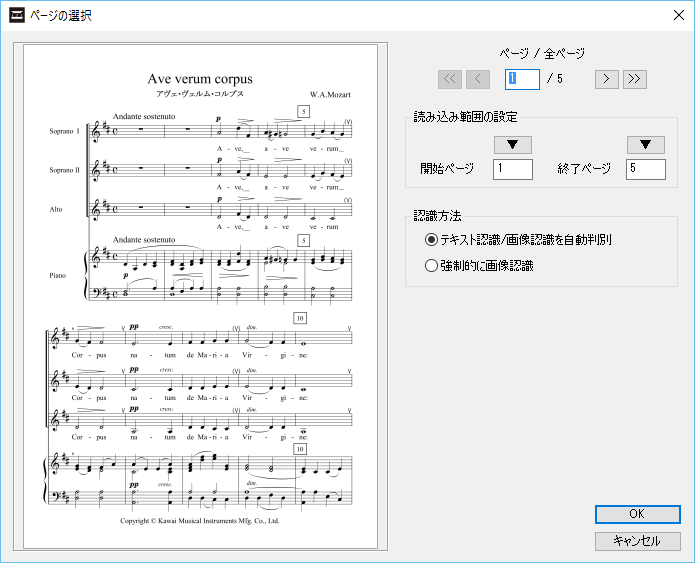
PDFファイルを登録すると、PDFのページ選択ダイアログボックスが表示されます。
右上の<や>ボタンを操作して各ページを確認しながら、 開始ページと終了ページを設定してください。 (▼ボタンで現在表示されているページを開始ページ、終了ページに設定できます。)
このとき、通常は テキスト認識/画像認識を自動判別 のオプションを選択してください。 テキストとして認識させた結果が思わしくなかったときは、 強制的に画像認識を選択します。
OKボタンをクリックすると、設定したページの画像が画像リストに表示されます。